
Des éléments significatifs du langage C#
1) Retour sur le type delegate
Ceci n'est pas une nouveauté, revenons réanmoins sur ce type un peu particulier car il joue un rôle central dans les nouveaux éléments de syntaxe C# 3 et 3.5.
On dit souvent que le type delegate est un type "pointeur sur une fonction". Faisons un retour en arrière pour revenir à son ancêtre en C : pointeur sur fonction.
1.a Les pointeurs sur fonction en C
Rien de tel qu'un petit exemple pour illustrer la notion, imaginons la situation simple :
Cet appel affichera 10, par appel de la fonction incremente.
Maintenant, déclarons un pointeur sur une fonction de même signature
que la fonction incremente :
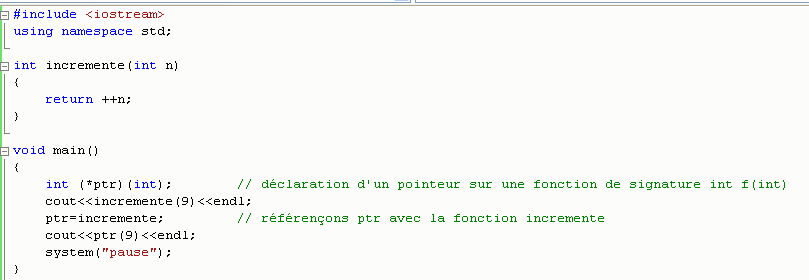
A l'exécution, on obtient bien sûr, le même résultat :
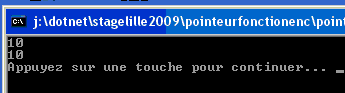
La ligne ptr = incremente laisse penser que le nom d'une fonction est
une adresse (un pointeur), confirmons-le en affichant aussi les valeurs
des fonctions :

Ce qui donne :
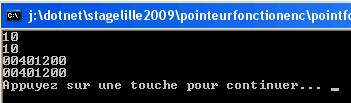
Le pointeur ptr pourra, si besoin, référencer une autre
fonction ; ajoutons une fonction decremente en concervant le code essentiel
:

Ce qui produira, sans surprise :
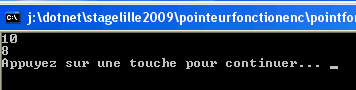
Notons que ptr ne peut référencer qu'une fonction dont la signature lui a été précisée à la déclaration : int f(int)
Pour terminer, rendons le code plus compact et utilisons le pointeur de fonction
comme un argument d'une fonction d'affichage :

Le résultat est identique au programme précédent.
Ainsi, ici, la fonction affiche prend un pointeur comme argument. Noter
la syntaxe de l'appel affiche(9, incremente) ; cet appel ne doit pas préciser
l'argument de la fonction incremente. Nous obtenons un code très
compact, qui certes perd un peu en lisibilité compte tenu des indirections
opérées...
L'intérêt principal de ce type de programmation est de proposer une liaison retardée (late-binding) en injectant du code à des endroits à priori inattendus.
1.b Les delegate en C#
Ecrivons maintenant en C# l'équivalent de la dernière version
:

L'effet est bien sûr le même :

Notons néanmoins quelques différences :
1.b.1 Le mot delegate déclare un type qui peut être
utilisé par la suite
Ainsi nous pourrions écrire :

Dans cette version nous déclarons
une variable d de type monDelegue. Il y a donc distinction classique
entre le type et la variable de ce type ; ceci permet également une signature
de la méthode affiche un peu moins obscure qu'en C!! (mais cela
ne va pas durer :-), cf plus loin)
1.b.2 Une seconde différence tient à la nature des delegate,
types plus élaborés qu'en C ; en effet il possible qu'un délégué
pointe sur plusieurs fonctions (multicast).
Pour montrer cela, on va un peu modifier les fonctionnalités des fonctions
afin de se concentrer sur l'essentiel :

Les fonctions incremente et decremente affichent maintenant le
résultat, le délégué a été modifié
en conséquence ; l'opérateur += ajoute une réference au
délégué ; ainsi le délégué pointe
sur une liste de deux fonctions. Ce qui donne à l'exécution :
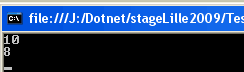
Si l'on trace le code, on constate bien que l'appel de d(9) engendre l'exécution des deux méthodes incremente et decremente, et cela dans l'ordre de leurs "inscriptions". L'opérateur -= retire de la liste pointée la dernière référence des fonctions "inscrites".
Remarques :
- L'inialisation monDelegue d = incremente est un racourci pour monDelegue d = new monDelegue(incremente);
- Le langage C proposait également ce type de service par l'intermédiaire des functors.
- La portée de la définition du délégué suit les règles générales de portée de C# (ici la portée est le namespace)
- Les delegate sont à la base des événements.
2) Les types génériques (ou templates ou types paramétrés)
La version 2.0 introduit un nouveau concept, cher à C++, les types génériques
(template en C).
Ainsi (comme en C) le type générique est annoncé par les
balises < et >. imaginons une classe Pile qui ne fait qu'ajouter ou retirer
des éléments (dernier entré). Les types génériques
permettent de ne présenter qu'une seule interface pour une classe générique
permettant de créer des piles d'entiers, de réels ou de chaînes
ou autres.
La classe Pile pourrait se présenter ainsi :

Le type générique est annoncé par <T> ; nous
pourrions, bien sûr, utiliser tout autre identificateur que T. Le type
générique T est utilisé à chaque fois que sa référence
est exigée. L'utilisation est simple :

Ce qui provoque :

A l'initialisation d'une pile, il faut indiquer le type réel ; ici le compilateur va générer une classe Pile typée par un string.
Nous pourrions créer, de la même manière, une pile d'entiers,
en utilisant la même interface :

Ce qui produit :

Une classe générique n'est pas réduite à un seul
type générique, ainsi une classe MaClasse pourait être déclarée
ainsi :
class MaClasse<T1><T2>. Les types génériques
peuvent représenter les types du framework ou tout type créé.
Une méthode peut aussi être générique, dans ses
arguments ou pour son type de retour :
void permute<T>(ref T a, ref T b)
{
T temp = a;
a = b;
b = temp;
}
int n1 =12;
int n2 = 9;
permute<int>(ref n1, ref n2);
Remarque : le dernier appel pourrait être réduit à permute(ref
n1, ref n2) ; en effet, à la compilation le langage est capable d'inférer
le type réel à partir du type des arguments. Pour voir ce qui
a été généré par le compilateur (outil Reflector)
:
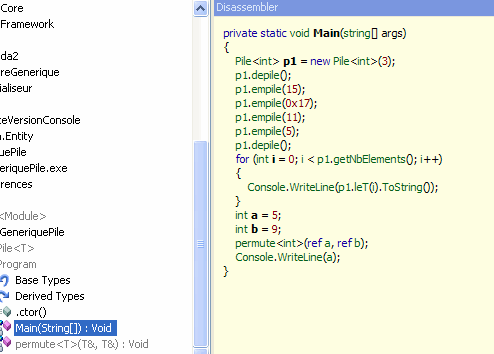
Remarque : Reflector est petit outil gratuit qui désassemble le fichier exe et montre ainsi le code réellement compilé et qui n'est pas toujours le code écrit.
Le framework (à partir de 2.0) propose ainsi des collections génériques
:
List<T> ou Dictionnary<Tcle><Tvaleur>
Plutôt que de partir d'une approche théorique sur les itérateurs,
posons le problème. Imaginons une situation simple où nous disposons
d'une classe Personne, réduite à deux attributs (nom et
âge) :
Ainsi qu'une méthode (redéfinie, ToString) qui retourne
la chaîne constituée des valeurs des attributs.

Nous disposons, par ailleurs, d'une classe conteneur qui contient des
personnes : la classe Groupe. Les objets Personne de chaque Groupe
sont placés dans un tableau.

Mais, et c'est là où se situe le problème, nous ne pouvons
pas demander à un Groupe d'itérer sur ses Personne.
Nous ne pouvons pas écrire quelque chose du genre :

La structure itérative foreach n'est pas acceptée ; elle ne l'est
pas car seules les classes énumérables peuvent bénéficier
de l'itérateur foreach. Une classe énumérable est une classe
qui peut présenter l'itérateur foreach pour parcourir sa
collection d'objets. En d'autres termes, la classe Groupe doit implémenter
l'interface IEnumerable, et donc fournir le code de la méthode
public IEnumerator GetEnumerator() (unique méthode de l'interface
IEnumerable).
Le code de la classe Groupe devient :

Maintenant le code :
Affiche bien :

La méthode GetEnumerator, imposée par l'interface, se
contente de parcourir le tableau et de retourner les éléments
dans une bien étrange instruction yield return. Par ailleurs,
le type de retour est un IEnumerator ; interface qui permet de parcourir
une collection, cf la description dans MSDN de l'interface IEnumerator:
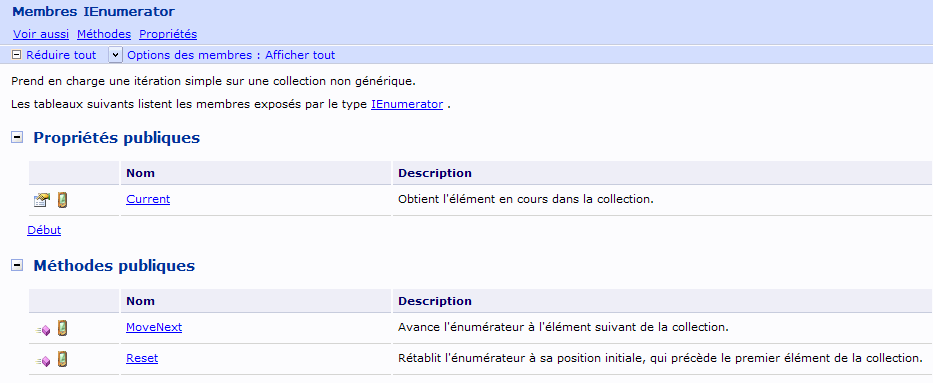
Pour résumer la situation, une classe conteneur peut bénéficier du foreach si elle est énumérable (interface IEnumerable) et si elle présente une méthode qui retourne un énumérateur, c'est à dire un mécanisme de parcours des éléments qu'elle veut exposer.
Mais qui construit cet énumérateur ? En fait c'est le framework et ce à partir de l'instruction yield return. Pour s'en convaincre, désassemblons le code de GetEnumerator (grâce à l'outil Reflector).
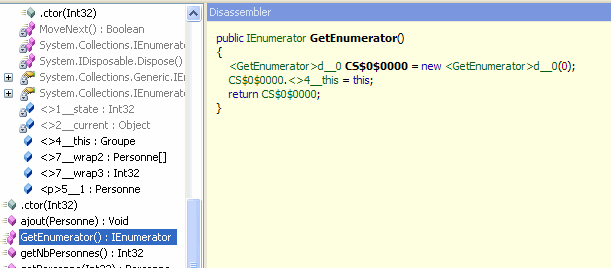
On peut voir que la méthode GetEnumerator() (fenêtre de droite)
instancie un objet de la classe <GetEnumerator>d_0 ; ainsi une
classe a été créée automatiquement par le compilateur.
Si on parcours la fenêtre de gauche on trouve cette classe :
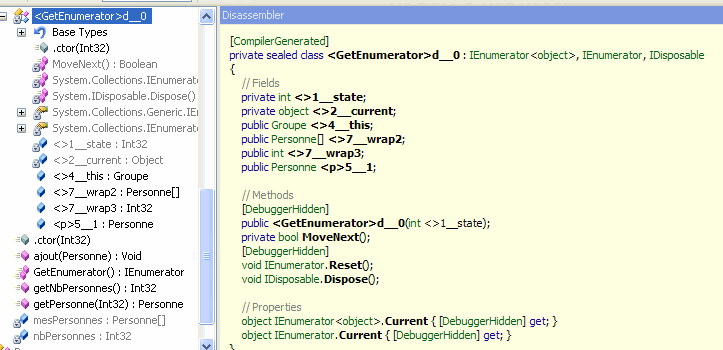
Des méthodes ont été générées, notamment MoveNext, Reset, Current ; méthodes demandées dans le contrat de l'interface IEnumerator (cf MSDN plus haut).
Il serait par exemple possible aussi de proposer une méthode qui filtre
certaines occurences des personnes :

Remarque : pour la démonstration, on a ajouté un accesseur sur l'âge (getAge)
Ceci produira, avec le même foreach du Main :
L'instruction yield return ne peut figurer que dans dans des fonctions retournant un IEnumerator ou directement un IEnumerable. Observons le mécanisme dans ce second cas en dehors de toute classe conteneur. Ecrivons une fonction Test (static) :

Si nous appelons cette fonction dans le Main, on constate à nouveau
ce résultat bien troublant :
![]()
Notons au passage que l'on peut itérer sur une fonction puisque celle-ci
retourne un IEnumerable !

Désassemblons la fonction :
Comme plus haut, la fonction a un code différent de celui écrit et il y a génération d'une classe :
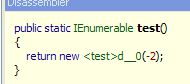
Cette classe dispose de champs qui vont permettre la mémorisation de la valeur et l'état de l'objet (ici chaque valeur "retournée" par yield return) courant :

La méthode MoveNext fait le travail de mise à jour :

Noter la dernière affectation dans chaque case qui permet d'itérer
en avançant pour le prochain appel de MoveNext.
Pour terminer ce survol des itérateurs, et pour ceux qui sont allergiques à yield return, rien n'interdit d'en rester à une version plus classique de l'itérateur, voici l'itérateur pour la classe Groupe :

Cet itérateur sera bien sûr créé et retourné
dans la méthode GetEnumerator :

4) Déclaration implicite de type
La version 3.0 propose une simplification de la syntaxe de déclaration
des variables ; il pouvait sembler redondant (dans la majorité des cas)
de faire le type de déclaration et d'initialisation suivants : Personne
P = new Personne(). Le langage propose désormais d'utiliser le mot var
:
var p = new Personne();
Rien de révolutionnaire là, le compilateur déduira de
l'initialisation le type de l'objet. Ceci procure un confort d'utilisation lorsque
notamment le type de retour d'une fonction n'est pas évident, par contre
:
- Le mot var doit être suivi de l'initialisation (new) ou de la
valeur ( var s = "toto";)
- Le type est défini à la compilation et ne peut être modifié
ensuite
- Il est possible bien sûr (et conseillé dans la majorité
des cas) de continuer à typer explicitement les variables dans la très
grande majorité des situations.
Le framework 3 propose d'enrichir des classes existantes par des méthodes dites "d'extension" ; cette ouverture n'est faite que pour des raisons techniques, liées au désir de MS de ne pas modifier des classes (pour la mise en oeuvre de linq, cf plus loin) en étendant des fonctionnalités.
La syntaxe doit utiliser une classe statique (sans constructeur et constituée uniquement de méthodes statiques) :

Noter l'utilisation très particulière ici de this.
L'appel à cette extension (sur les int) se fait tout naturellement ainsi :

6) Les méthodes anonymes et les expressions lambda
6.1 Les méthodes anonymes.
La version 2.0 du framework a introduit la notion de méthode anonyme ; comme son nom l'indique, il s'agit d'une méthode qui n'a pas de nom, par contre les méthodes anonymes ne concerne que les delegués.
Reprenons notre exemple : Pile<T>. Nous avions ajouté un
delegate au niveau du namespace (cf tp : delegate void deleg(); )
afin de gérer l'événement pilePleine. Dans le constructeur
de la pile, nous abonnions à l'événement un gestionnaire
(par défaut) :

Ainsi, il est possible de ne pas déclarer le gestionnaire d'événement
evtInitPilePleine en utilisant une méthode anonyme au moment de
l'inscription :

Le délégué pointe sur une fonction sans nom, dont le code
est présenté entre des accolades classiques. L'annonce en est
faite grâce au mot delegate jouant pour cette occasion un rôle
un peu différent. Comment ceci est-il possible ? C'est grâce au
compilateur qui va s'occuper de générer explicitement une méthode
conforme à la signature du delegate. Le compilateur se comporte comme
pour l'instruction yield return : il allège le travail du développeur
en générant automatiquement le code attendu.
Regardons ce que le compilateur à généré à
l'aide de l'outil Reflector :
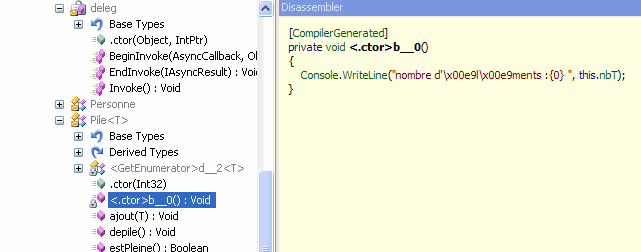
Une nouvelle méthode, générée par le compilateur
(attribut CompilerGenerated) est visible ; son code est identique à
la description inline de la méthode.
Le mécanisme semble simple : on peut déclarer inline le corps
d'une méthode déléguée, le compilateur se charge
de créer la bonne méthode. Mais l'intervention du compilateur
n'en reste pas là : modifions très légèrement le
code inline.

On déclare une variable (locale au constructeur) et on demande au délégué
d'afficher à chacun de ses appels cette variable incrémentée.
Non seulement le compilateur accepte ce code (troublant au niveau de la portée
de nbAppels) mais il propose un résultat pour le moins déroutant
!
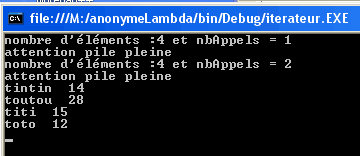
L'incrémentation se fait alors que nbAppels (variable locale) est détruite à la fin de l'exécution du constructeur !! nbAppels semble détruit...pour le constructeur mais pas pour tout le monde !!
Replongeons-nous dans le code généré par le compilateur:
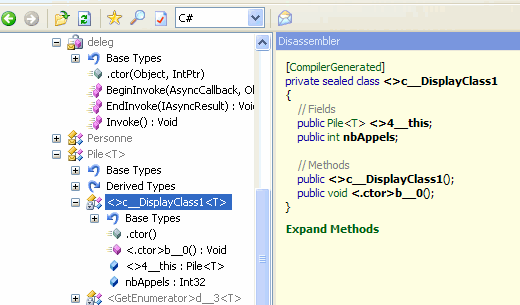
Le compilateur a créé une classe cette fois (et pas seulement une méthode), nbAppels en est devenu un champ ! Chaque nouvel appel de l'événement entraîne une incrémentation du champ nbAppels.
Ainsi, selon le contexte de l'appel de la méthode inline, le compilateur génère une méthode ou une classe.
6.2 Les expressions lambda
Une expression lambda peut être utilisée lorsqu'un délégué
est normalement nécessaire ; ceci permet de simplifier l'écriture
de la fonction. Une expression lambda comprend :
- Des paramètres
- Le signe =>
- Une expression résultat.
Quelques expressions :
( n) => n%2
( a, b) => a+b
Mise en oeuvre :
| Définition du type délégué voulu |
|
| Déclaration d'un délégué conforme | |
| Appel du délégué |  |
Il peut sembler pénible d'avoir à définir le type deleg2 ; C# propose un type délégate générique (Func) qui allège l'écriture :
| Utilisation de Func et déclaration d'un délégué conforme | |
| Appel du délégué | |
Dans ces deux exemples, l'utilisation d'un délégué n'est bien sûr pas nécessaire pour faire le traitement attendu.
Construisons un exemple où l'utilisation des expressions lambda trouvent plus de sens et de vertu :
L'objectif sera de proposer des filtres sur une liste de nombres (stockée dans une ArrayList)

L'appel ![]() utilise une expression lambda pour filtrer les multiples de 9.
utilise une expression lambda pour filtrer les multiples de 9.
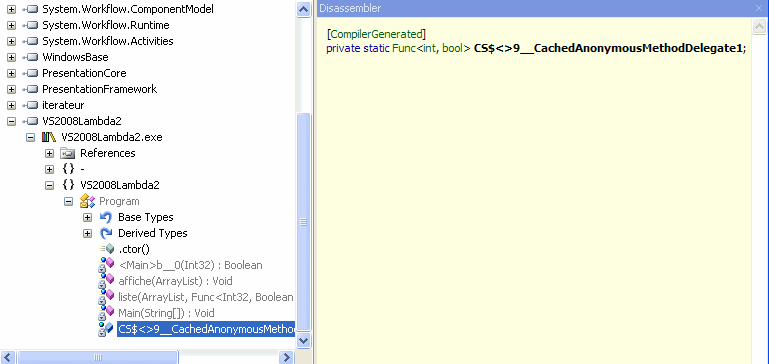
Si nous demandons à Reflector de montrer le code généré
par le compilateur, deux choses à noter :
- La déclaration explicite d'un type délégate typé
- La définition de la fonction déléguée conforme
au delegate :
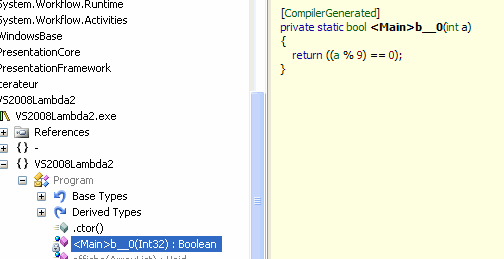
Les expressions lambda sont des facilités offertes au développeur affranchi des déclarations des delegate et d'un code impératif.
A l'exécution, nous obtenons, bien sûr, la liste :

Nous pourrions proposer d'autres filtres :

Répétons-le encore une fois, l'expression lambda peut être remplacée par du code plus traditionnel ; il serait néanmoins dommage de ne pas profiter de la puissance du compilateur ici.
Le dernier point abordé porte sur l'initialisation d'objet, sans déclarer explicitement de classe ; modifions un peu le code du tp "capitales" :

La ligne surlignée utilise les types anonymes (mot var) et initialise
un objet cap, sans classe associée. Ceci permet de "récupérer"
les champs (num, lib) comme pour une classe "normale". L'appel
suivant :

produira :
